about me
I'm a 1st year MSc student Bioinformatics and Biocomplexity at the Utrecht University with a broad interest, always looking to learn new things. Visualizing and gaining insight into data is something I enjoy doing. The complexities of biological systems fascinate me, I believe the multidisciplinary field of bioinformatics is the key to understanding these systems.
Hobbies
Besides Bioinformatics I of course also enjoy a range of other things. I am a huge music fan, I love listening to music and finding new genres to enjoy. Furthermore, I enjoy bouldering. I like the challenge of solving boulder problems.
Projects
I enjoy to push myself with projects, here are a few which I've produced over the past years.
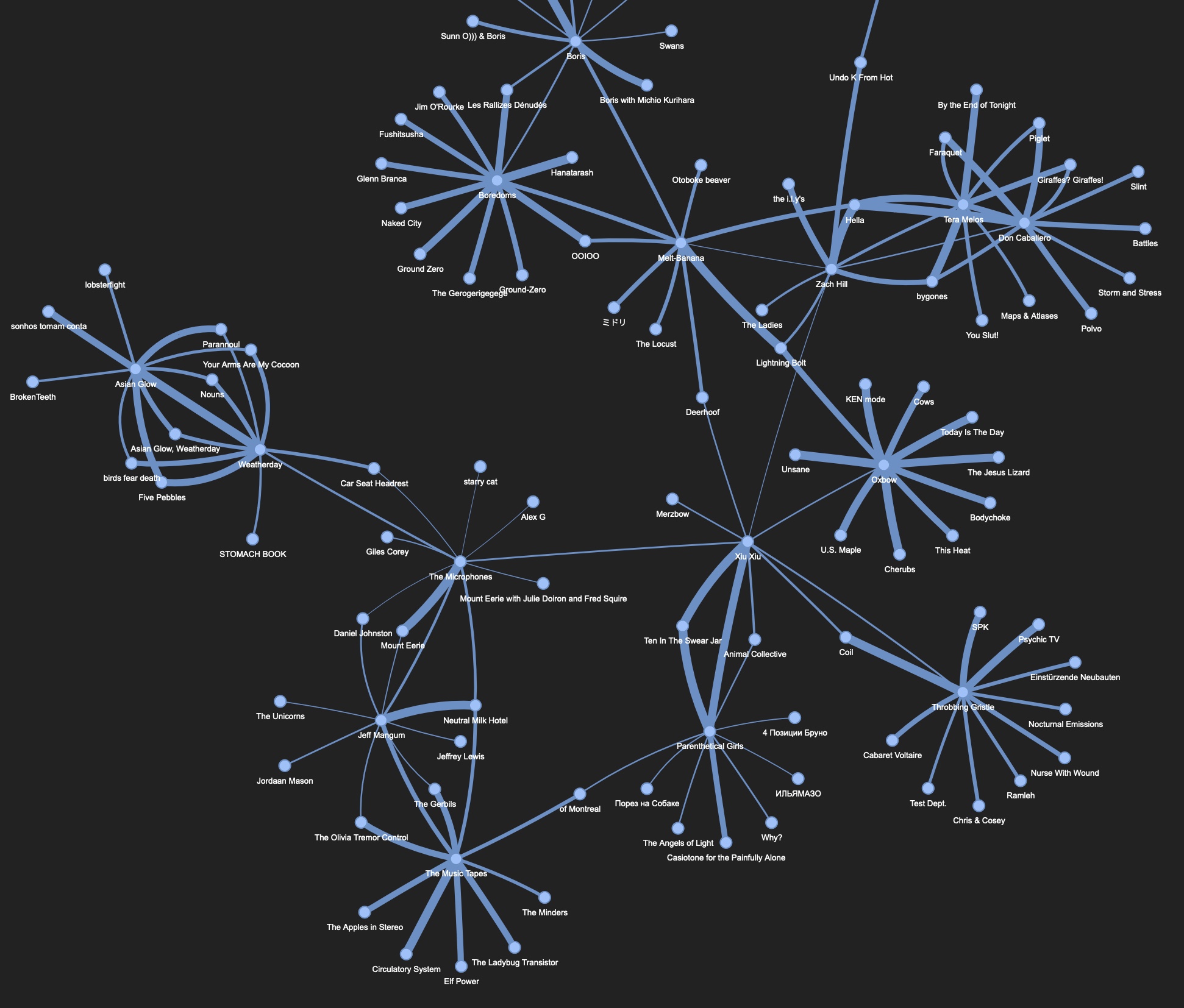
Musician Recommendation Graph
This tool asks the user for one or more musician. it then uses the last.fm api to produce a graph of related artists.
Rosalind.info
Rosalind is a platform for learning bioinformatics through problem solving. I've solved a quite few of these problems, currently being in the 98th percentile of its users.
Hovercraft
In my final year of VWO I built a hovercraft as a project. The hovercraft was controlled using an arduino which could be connected to your phone. It was a fun project and I learned a lot from it.
Terminal Mandelbrot Viewer
I wrote a Mandelbrot viewer which can be run in the terminal. It uses the numpy library to calculate the Mandelbrot set. The getkey library is used to explore the Mandelbrot set using user inputs.

FASTQ Parser Challenge
As an exercise to learn new programming languages I've written fastq parsers in a few different languages. The languages I've used are: Python, Rust, Lua, AWK, Bash, Haskell, Java, Julia, and R. In addition to the core fastq parsing functionality some include extra feaetures such as a sliding window sequence trimmer or a N50 read statistic.
16S rRNA Classifier
I wrote a simple 16S rRNA taxonomic classifier script. It compares the sequence to other 16 rRNA sequences and uses the overlap percentage to estimate the taxa. The tool can classify around 60% of sequences up to its Order.
More projects can be found on my github page